
Benchmark Early and Red Team Often
A Framework for Assessing and Managing Dual-Use Hazards of Ai Foundation Models
Keywords:
agi safety, cybersecurity, artificial general intelligence, ai safetyAbstract
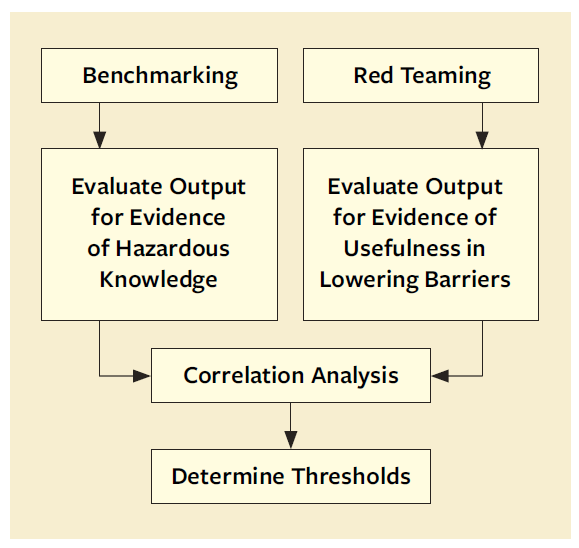
A concern about cutting-edge or “frontier” AI foundation models is that an adversary may use the models for preparing chemical, biological, radiological, nuclear (CBRN), cyber, or other attacks. At least two methods can identify foundation models with potential dual-use capability; each method has advantages and disadvantages:
A. Open benchmarks (based on openly available questions and answers), which are low-cost but accuracy-limited by the need to omit security-sensitive details, and
B. Closed red team evaluations (based on private evaluation by CBRN and cyber experts), which are higher in cost but can achieve higher accuracy by incorporating sensitive details.
We propose a research and risk-management approach using a combination of methods including both open benchmarks and closed red team evaluations, in a way that leverages advantages of both methods.
We recommend that one or more groups of researchers with sufficient resources and access to a range of near-frontier and frontier foundation models:
1. Run a set of foundation models through dual-use capability evaluation benchmarks and red team
evaluations, then
2. Analyze the resulting sets of models’ scores on benchmark and red team evaluations to see how
correlated those are.
If, as we expect, there is substantial correlation between the dual-use potential benchmark scores and the red team evaluation scores, then implications include the following:
• The open benchmarks should be used frequently during foundation model development as a quick,
low-cost measure of a model’s dual-use potential; and
• If a particular model gets a high score on the dual-use potential benchmark, then more in-depth red
team assessments of that model’s dual-use capability should be performed.
We also discuss limitations and mitigations for our approach, e.g., if model developers try to game benchmarks by including a version of benchmark test data in a model’s training data.
Downloads
Published
How to Cite
Issue
Section
Categories
License
Copyright (c) 2024 Anthony Barrett

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.
